
Michal Škrabal, Zuzana Laubeová, Barbora Štěpánková (eds)
 Od uveřejnění Fergusonovy základní studie v roce 1959 se objevují pokusy aplikovat diglosii na češtinu. Diglosie, tj. funkčně diferencované používání dvou jazykových variet (vysoké a nízké) v jedné společnosti, je zde zpravidla spatřována v odlišném užívání spisovné a obecné češtiny. Původně binárně vymezený pojem diglosie je však v současnosti narušován ze dvou stran: jednak možností specializovanějšího a poučenějšího lingvistického popisu, jednak způsobem chápání komunikačního prostředí, jež máme v rámci jazyka k dispozici. Předkládaná monografie nasvěcuje problematiku diglosie v češtině z různých úhlů pohledu: převažuje ten kvantitativní, zaměřený na oblast morfologie, lexika a stylových žánrů; kvalitativní pohled je pak reprezentován sociolingvistickým přístupem zkoumajícím jazykový management. Metodologickým svorníkem obou perspektiv jsou korpusová data: kromě reprezentativního korpusu psané češtiny a dvou mluvených korpusů byly využity i korpusy specializované. Právě tato empirická data, v objemech ještě před pár dekádami zcela nemyslitelných, naše vědomosti o diglosii v češtině podstatně korigují; spolu s významnými technologicko-společenskými změnami pak odhalují problematičnost tohoto konceptu, resp. obrušují jeho ostrou binaritu ve prospěch fuzzy povahy daného jevu.
Od uveřejnění Fergusonovy základní studie v roce 1959 se objevují pokusy aplikovat diglosii na češtinu. Diglosie, tj. funkčně diferencované používání dvou jazykových variet (vysoké a nízké) v jedné společnosti, je zde zpravidla spatřována v odlišném užívání spisovné a obecné češtiny. Původně binárně vymezený pojem diglosie je však v současnosti narušován ze dvou stran: jednak možností specializovanějšího a poučenějšího lingvistického popisu, jednak způsobem chápání komunikačního prostředí, jež máme v rámci jazyka k dispozici. Předkládaná monografie nasvěcuje problematiku diglosie v češtině z různých úhlů pohledu: převažuje ten kvantitativní, zaměřený na oblast morfologie, lexika a stylových žánrů; kvalitativní pohled je pak reprezentován sociolingvistickým přístupem zkoumajícím jazykový management. Metodologickým svorníkem obou perspektiv jsou korpusová data: kromě reprezentativního korpusu psané češtiny a dvou mluvených korpusů byly využity i korpusy specializované. Právě tato empirická data, v objemech ještě před pár dekádami zcela nemyslitelných, naše vědomosti o diglosii v češtině podstatně korigují; spolu s významnými technologicko-společenskými změnami pak odhalují problematičnost tohoto konceptu, resp. obrušují jeho ostrou binaritu ve prospěch fuzzy povahy daného jevu.
Škrabal, M., Laubeová, Z., Štěpánková, B. (eds): Korpusové přístupy k české diglosii. NLN, Praha 2022.
ISBN: 978-80-7422-944-2
Tomáš Káňa
 Deminutiva, čili zdrobněliny se často uvádějí jako typický znak češtiny a jejich množství jako důkaz bohatosti jazyka. Tato studie založená na velkém množství autentického jazykového materiálu však dokládá, že se spoustou zdrobnělých slov vlastně nic nezdrobňuje a že se často jedná o jeden z běžných prostředků české slovotvorby.
Deminutiva, čili zdrobněliny se často uvádějí jako typický znak češtiny a jejich množství jako důkaz bohatosti jazyka. Tato studie založená na velkém množství autentického jazykového materiálu však dokládá, že se spoustou zdrobnělých slov vlastně nic nezdrobňuje a že se často jedná o jeden z běžných prostředků české slovotvorby.
Příklady i nová systematizace deminutivních prostředků vycházejí ze živého současného jazyka uloženého v elektronických korpusech jednojazyčných i paralelních. Publikace přináší také přehled nejdůležitějších statí, která byly o deminutivech napsány, zodpovídá některé otázky, které dřív uspokojivě zodpovězeny nebyly, a podává vhled na protějšky tohoto fenoménu v jiných jazycích – především v němčině a v angličtině.
Káňa, T.: Česká deminutiva: korpusová studie. NLN, Praha 2022.
ISBN: 978-80-7422-893-3
Václav Cvrček, Zuzana Laubeová, David Lukeš, Petra Poukarová, Anna Řehořková, Adrian Jan Zasina
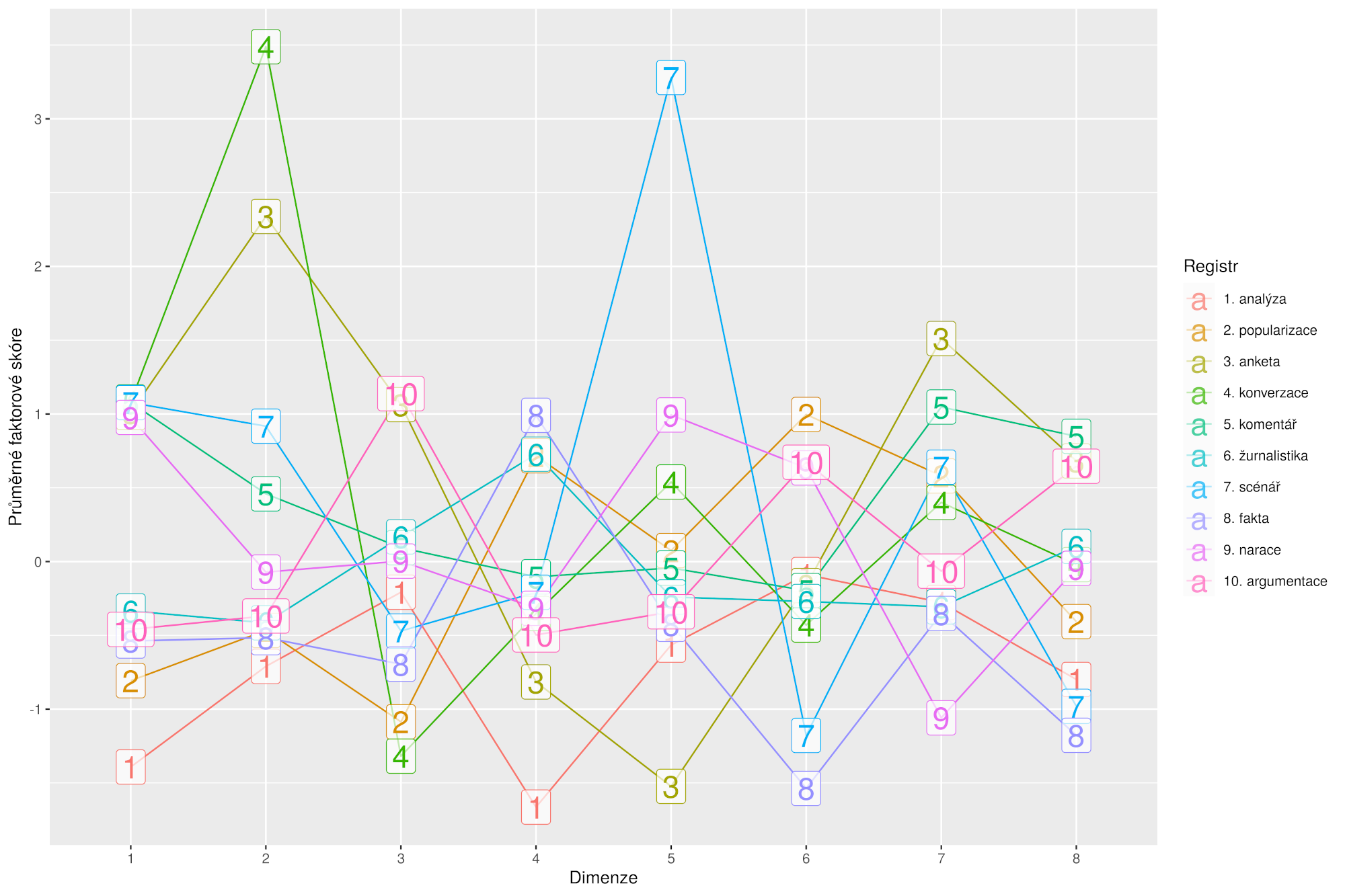
 Při pohledu na texty a jejich různorodost můžeme uplatnit dvě perspektivy: buď se zaměříme na vnější charakteristiky textu, jako je obálka, komunikační médium, grafická stránka atp., nebo zkoumáme použité jazykové prostředky, např. jak často se v textu používají otázky nebo zda je v něm podmiňovací způsob. Zde nám půjde především o tu druhou, vnitrotextovou perspektivu, která pomáhá identifikovat v jazyce registry. Ty můžeme vnímat – obdobně jako rejstříky na varhanách – jako alternativní způsoby, jak vyjádřit obsah, který chceme sdělit. O tom, jak tyto registry v jazyce identifikovat a charakterizovat pomocí empirických a kvantitativních metod na základě rozsáhlých korpusových dat, pojednává tato knížka. Inspiraci čerpá ze slavného multidimenzionálního přístupu Douglase Bibera, který se zde vůbec poprvé ve větším měřítku uplatňuje na češtinu.
Při pohledu na texty a jejich různorodost můžeme uplatnit dvě perspektivy: buď se zaměříme na vnější charakteristiky textu, jako je obálka, komunikační médium, grafická stránka atp., nebo zkoumáme použité jazykové prostředky, např. jak často se v textu používají otázky nebo zda je v něm podmiňovací způsob. Zde nám půjde především o tu druhou, vnitrotextovou perspektivu, která pomáhá identifikovat v jazyce registry. Ty můžeme vnímat – obdobně jako rejstříky na varhanách – jako alternativní způsoby, jak vyjádřit obsah, který chceme sdělit. O tom, jak tyto registry v jazyce identifikovat a charakterizovat pomocí empirických a kvantitativních metod na základě rozsáhlých korpusových dat, pojednává tato knížka. Inspiraci čerpá ze slavného multidimenzionálního přístupu Douglase Bibera, který se zde vůbec poprvé ve větším měřítku uplatňuje na češtinu.
Errata: Na straně 121 je uvedena nesprávná verze obrázku č. 24. Správný obrázek je k dispozici zde.
Cvrček, V., Laubeová, Z., Lukeš, D., Poukarová, P., Řehořková, A., Zasina, A. J.: Registry v češtině. NLN, Praha 2020.
ISBN: 978-80-7422-754-7
Lucie Chlumská
 Ačkoli překladová literatura tvoří v českém prostředí více než třetinu knižní produkce, čeština v překladech doposud nebyla podrobena systematické kvantitativní analýze. Cílem tohoto svazku je proto popsat charakteristické rysy překladové češtiny ve srovnání s češtinou v původně českých (nepřekladových) textech pomocí metod korpusové translatologie. Analýza byla provedena na základě rozsáhlého jednojazyčného srovnatelného korpusu Jerome, který zahrnuje beletrii i odbornou literaturu a svým složením z hlediska zdrojových jazyků odráží reálnou situaci v ČR (výrazně převažují překlady z angličtiny). Inspiračním zdrojem práce se stal koncept tzv. překladových univerzálií, tj. údajných typických jazykových rysů, jež by měly být společné všem překladovým textům. Pozornost je věnována především simplifikaci, konvergenci a obecným frekvenčním charakteristikám, vč. porovnání výskytu slovních druhů a typických slovních kombinací v překladech a nepřekladových textech.
Ačkoli překladová literatura tvoří v českém prostředí více než třetinu knižní produkce, čeština v překladech doposud nebyla podrobena systematické kvantitativní analýze. Cílem tohoto svazku je proto popsat charakteristické rysy překladové češtiny ve srovnání s češtinou v původně českých (nepřekladových) textech pomocí metod korpusové translatologie. Analýza byla provedena na základě rozsáhlého jednojazyčného srovnatelného korpusu Jerome, který zahrnuje beletrii i odbornou literaturu a svým složením z hlediska zdrojových jazyků odráží reálnou situaci v ČR (výrazně převažují překlady z angličtiny). Inspiračním zdrojem práce se stal koncept tzv. překladových univerzálií, tj. údajných typických jazykových rysů, jež by měly být společné všem překladovým textům. Pozornost je věnována především simplifikaci, konvergenci a obecným frekvenčním charakteristikám, vč. porovnání výskytu slovních druhů a typických slovních kombinací v překladech a nepřekladových textech.
Chlumská, L.: Překladová čeština a její charakteristiky. NLN. Praha 2017.
ISBN: 978-80-7422-621-2
Sborník příspěvků k 70. narozeninám prof. Karla Kučery
Martin Stluka, Michal Škrabal (eds)
 Dvacátý pátý svazek řady Studie z korpusové lingvistiky je věnován spoluzakladateli Českého národního korpusu, prof. PhDr. Karlu Kučerovi, CSc., který v roce 2017 oslaví své významné životní jubileum (narozen 3. dubna 1947 v Chlumčanech u Loun).
Dvacátý pátý svazek řady Studie z korpusové lingvistiky je věnován spoluzakladateli Českého národního korpusu, prof. PhDr. Karlu Kučerovi, CSc., který v roce 2017 oslaví své významné životní jubileum (narozen 3. dubna 1947 v Chlumčanech u Loun).
Vystudoval češtinu a angličtinu na FF UK, dlouhodobě působil v Ústavu českého jazyka a teorie komunikace a od 90. let také v Ústavu Českého národního korpusu, kde setrvává dodnes. Během své mnohaleté pedagogické a vědecké činnosti se stal ve svém oboru doma i ve světě uznávanou kapacitou. Je autorem řady odborných knižních i časopiseckých publikací a odborných recenzí, editorem historických spisů. Vědeckou pozornost věnuje mnoha jazykovým aspektům. V současnosti je to zejména otázka diachronního korpusového zpracování češtiny, v dobách dřívějších úspěšně propojoval svůj zájem o studium starších fází češtiny se zkoumáním jazyka menšin žijících v zahraničí (zejména těch českých v USA). Předkládaný sborník v sobě zahrnuje jak odborné příspěvky zabývající se jazykem a jeho zpracováním z různých úhlů pohledu, tak texty vzpomínkové a humorně laděné. V jejich syntéze se plně zrcadlí osobnost prof. Karla Kučery, na jehož „Liſku a čbán“ vzpomíná nejeden student pražské bohemistiky.
Stluka, M., Škrabal, M. (eds): Liſka a czban – Sborník příspěvků k 70. narozeninám prof. Karla Kučery. NLN. Praha 2017.
ISBN: 978-80-7422-563-5
Dominika Kováříková
 Kniha představuje novou metodu automatického vyhledávání termínů v odborných textech, která je založena na data miningu, tedy na vytěžování informací z velkých objemů (korpusových) dat.
Kniha představuje novou metodu automatického vyhledávání termínů v odborných textech, která je založena na data miningu, tedy na vytěžování informací z velkých objemů (korpusových) dat.
Výzkum je zaměřen nejen na samotnou úspěšnost rozpoznávání, tedy na co nejvyšší počet správně vyhledaných termínů, ale v první řadě na vlastnosti, které při identifikaci jednoslovných a víceslovných termínů hrají nejdůležitější roli. Tím přispívá k prohloubení našich znalostí o termínech a o terminologii obecně. Můžeme konstatovat, že automatické vyhledávání jazykových jevů může přispět k jejich bližšímu poznání a že i čistě kvantitativní přístup, jako je data mining, je vhodný pro zkoumání lingvistického (korpusového) materiálu.
Kováříková, D.: Kvantitativní charakteristiky termínů. NLN. Praha 2017.
ISBN: 978-80-7422-561-1
Anna Čermáková, Lucie Chlumská, Markéta Malá (eds)

Od devadesátých let minulého století, kdy byl vytvořen první paralelní, norsko-anglický korpus, zaznamenala kontrastivní korpusová lingvistika rychlý rozvoj a korpusový materiál a metody se začaly široce uplatňovat i v translatologii. Kniha mapuje současný stav a trendy v obou těchto oblastech výzkumu opírajících se o využití překladových paralelních a srovnatelných korpusů. Vedle „tradičních“ korpusových kontrastivních a translatologických studií porovnávajících různé jazykové jevy a vyjadřování jazykových funkcí v několika jazycích (s oporou v datech paralelního korpusu InterCorp) obsahuje kniha také kapitoly, které ukazují na rozdíly mezi překladovou a nepřekladovou češtinou (na srovnatelných datech korpusu Jerome). Představuje tak širokou škálu metod, které se mohou v kontrastivně-korpusovém výzkumu uplatnit, ale ukazuje zároveň i na dosud existující omezení tohoto typu výzkumu spočívající zejména v rozsahu a omezené stylové rozmanitosti dostupných dat.
Čermáková, A., Chlumská, L., Malá, M. (eds): Jazykové paralely. NLN. Praha 2016.
ISBN: 978-80-7422-557-4
Vladimír Petkevič

V tomto svazku je na materiálu velkých korpusů řady SYN (SYN2010, SYN-2013PUB, SYN2015 a SYN) podrobně popsána morfologická homonymie v češtině, tj. homonymie slovních tvarů a jejich typů. Popis se zaměřuje jednak na morfologii vlastní, tj. vnitroparadigmatickou, jednak na morfologii nevlastní, tedy morfologii tvarů patřících do různých tvarových systémů téhož slovního druhu, odlišných slovních druhů nebo odlišných lexikálních jednotek. Práce dokládá nejen velkou rozmanitost typů morfologické homonymie v češtině, ale i to, jak nečekaně velkým množstvím víceznačných slovních tvarů dnešní čeština disponuje. Detailní klasifikace materiálové základny morfologických homonym v češtině může přispět nejen k hlubšímu teoretickému poznání morfologie českého slova, ale i napomoci řešení praktických problémů korpusové lingvistiky, jaké představuje například další zlepšování morfologického značkování textů současné češtiny, jejich syntaktické analýzy a úkolů souvisejících.
Petkevič, V.: Morfologická homonymie v současné češtině. NLN. Praha 2014.
ISBN: 978-80-7422-367-9
Tomáš Jelínek

Tento svazek představuje rozbor vztahu mezi skladebními funkcemi na jedné straně a slovními druhy a pády slov na straně druhé.Práce vychází z korpusu SYN2005, automaticky syntakticky anotovaného podle vzoru analytické roviny Pražského závislostního korpusu. Ukazuje, jak často se které skladební funkce realizují různými slovními druhy a různými pády flektivních slov, umožňuje také srovnání frekvence jevů podle žánrových subkorpusů. Navazuje na publikaci Statistiky češtiny, kterou doplňuje o syntaktický pohled.
Jelínek, T.: Skladební funkce a pád v korpusu: Frekvenční analýza. NLN. Praha 2015.
ISBN: 978-80-7422-366-2
Vladimír Petkevič, Ana Adamovičová, Václav Cvrček (eds)
 Jubilejní dvacátý svazek řady Studie z korpusové lingvistiky jsme věnovali jejímu zakladateli prof. Františku Čermákovi, který se v roce 2015 dožívá významného životního jubilea. Prof. PhDr. František Čermák, DrSc. (narozen v Praze 30. ledna 1940) je doma i ve světě uznávanou vědeckou kapacitou. Je autorem či spoluautorem 11 monografií, 17 slovníků (překladových, výkladových, frekvenčních), autorem bezpočtu odborných recenzí, editorem a překladatelem. Jeho jméno je spojováno s koncepcí a zpracováním rozsáhlého a mezinárodně uznávaného Slovníku české frazeologie a idiomatiky. Hlavním životním vědeckým počinem je však založení a dvacetileté ideové vedení Ústavu Českého národního korpusu FF UK, čímž položil zcela nový základ české empirické lingvistice v ČR. Předkládaný sborník je tematicky velmi pestrý, obsahuje příspěvky zabývající se lexikologií, frazeologií, korpusovou lingvistikou, ale také jazykovou kulturou či morfologií, čímž reflektuje košatost vědecké osobnosti prof. Čermáka a jeho široký rozhled po jazycích a jazykovědě.
Jubilejní dvacátý svazek řady Studie z korpusové lingvistiky jsme věnovali jejímu zakladateli prof. Františku Čermákovi, který se v roce 2015 dožívá významného životního jubilea. Prof. PhDr. František Čermák, DrSc. (narozen v Praze 30. ledna 1940) je doma i ve světě uznávanou vědeckou kapacitou. Je autorem či spoluautorem 11 monografií, 17 slovníků (překladových, výkladových, frekvenčních), autorem bezpočtu odborných recenzí, editorem a překladatelem. Jeho jméno je spojováno s koncepcí a zpracováním rozsáhlého a mezinárodně uznávaného Slovníku české frazeologie a idiomatiky. Hlavním životním vědeckým počinem je však založení a dvacetileté ideové vedení Ústavu Českého národního korpusu FF UK, čímž položil zcela nový základ české empirické lingvistice v ČR. Předkládaný sborník je tematicky velmi pestrý, obsahuje příspěvky zabývající se lexikologií, frazeologií, korpusovou lingvistikou, ale také jazykovou kulturou či morfologií, čímž reflektuje košatost vědecké osobnosti prof. Čermáka a jeho široký rozhled po jazycích a jazykovědě.
Errata: Uveřejňujeme správnou verzi článku Ilony Kořánové Máte problém se soustředit? (str. 231). Ve sborníku byla omylem publikována starší verze textu, za což se autorce omlouváme.
Petkevič, V., Adamovičová, A., Cvrček, V. (eds): Radost z jazyků – Sborník příspěvků k 75. narozeninám prof. Františka Čermáka. NLN. Praha 2014.
ISBN: 978-80-7422-361-7
František Čermák
Originální a dosud nikde neexistující systematický vhled do jazyka, který nabízí věrný a  hloubkový pohled na povahu a chování takového typu slov jako najevo, vstříc, úkor, dokořán, kterým se nikdy pozornost nevěnovala.
hloubkový pohled na povahu a chování takového typu slov jako najevo, vstříc, úkor, dokořán, kterým se nikdy pozornost nevěnovala.
Vstupními zdroji pro tento slovník byl stomilionový korpus češtiny (SYN), frazeologický slovník a další zdroje; tato data byla zpracována několika programy a následnou manuální analýzou vedoucí ke konečnému tvaru. Takto se k uživateli dostává celkem 3623 monokolokabilních slov (slovních tvarů), vybavených především frekvencemi a to ve dvou podobách.
Čermák, F.: Periferie jazyka – Slovník monokolokabilních slov. NLN. Praha 2014.
ISBN: 978-80-7422-349-5
Pavel Vondřička
 The goal of the study is a design of a framework for formalized representation of lexical knowledge, as presented in bilingual dictionaries. Little research has been done on the possibilities of representation and storage of the knowledge acquired in the process of lexicographical analysis and used in the synthesis of dictionary entries. Separation of content from a particular form would allow for re-use of the data for several purposes (including NLP) and for flexible customization of dictionaries for different users.
The goal of the study is a design of a framework for formalized representation of lexical knowledge, as presented in bilingual dictionaries. Little research has been done on the possibilities of representation and storage of the knowledge acquired in the process of lexicographical analysis and used in the synthesis of dictionary entries. Separation of content from a particular form would allow for re-use of the data for several purposes (including NLP) and for flexible customization of dictionaries for different users.
In the first part, general abstract principles of representation of lexical knowledge are sought. The structure of different dictionary entries is analyzed. Modern technical approaches, which may contribute to an efficient representation of the knowledge, are summarized and a generic abstract model for its representation is defined in terms of objects and relations, together with a proposal for a modular implementation separating the language and dictionary specific components.
The second part demonstrates the use of the model for one particular task: a detailed description of a group of Norwegian nouns in contrast with their Czech equivalents. The nouns are analyzed and a possible representation of the knowledge is presented using the proposed generic model and task specific specifications.
Vondřička, P.: Formalized contrastive lexical description: a framework for bilingual dictionaries. LINCOM Studies in Computational Linguistics, 2014.
ISBN 978-3-86288-428-5
František Čermák
For centuries, the habit of collecting proverbs, has been domain of interest and  subsequent study attracting ethnographers and historians, primarily, though later on a number of scholars from other disciplines have made the field now truly interdisciplinary. Only rather recently, also linguistics, notably lexicology and phraseology, has started to offer linguistic insights into proverbs, too. However, unlike other disciplines, corpus linguistics approaches, used here enable more general insights using large amounts of data, also in paremiology. In general, lexical studies published here aim to point to what any proverb cannot do without, namely to words it is built on, its meaning and use.
subsequent study attracting ethnographers and historians, primarily, though later on a number of scholars from other disciplines have made the field now truly interdisciplinary. Only rather recently, also linguistics, notably lexicology and phraseology, has started to offer linguistic insights into proverbs, too. However, unlike other disciplines, corpus linguistics approaches, used here enable more general insights using large amounts of data, also in paremiology. In general, lexical studies published here aim to point to what any proverb cannot do without, namely to words it is built on, its meaning and use.
This volume, devoted to a number of languages, their proverbs and lexicon is an attempt along these lines trying to bring together what has been published in many places. Twelve contributions offered here are based on modified and improved versions of what has come out elsewhere before Thus, the reader may inspect and compare them collected side by side here for the first time. Broadly, the book may be viewed as made up of items dealing with General Aspects (I, first three items), contributions to Lexicon and Pragmatics proper (II, the following five items), supplemented by studies on Specific topics (III, the last four contributions) where also paremiological minima are to be found.
Čermák, F: Proverbs: Their Lexical and Semantic Features. Proverbium in cooperation with the Institute of the Czech National Corpus, Supplement Series, Vol. 37, ed. W. Mieder. The University of Vermont, Burlington, Vermont 2014.
ISBN: 978-0-9846456-1-9
František Čermák
Tento slovník přísloví obsahuje téměř pět set nejčastějších českých přísloví dneška. Uvádí  jejich podobu, současný význam i způsob užití.
jejich podobu, současný význam i způsob užití.
Běžná představa, že přísloví-tento prastarý útvar, který má každý jazyk-se v naší uspěchané době už neužívá či dokonce že nevznikají nová, neodpovídá realitě. Přísloví žijí i dnes, jakkoliv se jejich podoba i způsob užití pomalu mění a přibývají i nová. Součástí slovníku jsou také zaznamenané a většinou tedy autentické příklady použití přísloví, stejně jako výklad jejich významu i kontextu, ve kterém se s nimi setkáváme.
Čermák, F.: Základní slovník českých přísloví. Nakladatelství Lidové noviny. Praha 2013.
ISBN: 978-80-7422-258-0
Michal Křen
Tento svazek představuje diachronní pohled na synchronní psané korpusy řady SYN,  které zachycují blízké stavy jazyka. Cílem práce bylo především zjištění možností a mezí detekce vývojových tendencí v jazyce na materiálu korpusů této řady, mezi vedlejší výstupy patří také vyhodnocení jejich složení. Popisovaná metoda je aplikována v několika variantách na různě definované subkorpusy a podrobně vyhodnocena na úrovní lemmat a lexikálních kombinací. Protože je obtížné odlišit zárodky diachronních posunů od přirozeně existující synchronní variability, je statisticky zjištěná významnost frekvenčních rozdílů jednotlivých výrazů zpětně ověřována na korpusech a interpretace výsledků je korigována informacemi o jejich přesném složení.
které zachycují blízké stavy jazyka. Cílem práce bylo především zjištění možností a mezí detekce vývojových tendencí v jazyce na materiálu korpusů této řady, mezi vedlejší výstupy patří také vyhodnocení jejich složení. Popisovaná metoda je aplikována v několika variantách na různě definované subkorpusy a podrobně vyhodnocena na úrovní lemmat a lexikálních kombinací. Protože je obtížné odlišit zárodky diachronních posunů od přirozeně existující synchronní variability, je statisticky zjištěná významnost frekvenčních rozdílů jednotlivých výrazů zpětně ověřována na korpusech a interpretace výsledků je korigována informacemi o jejich přesném složení.
Křen, M.: Odraz jazykových změn v synchronních korpusech. Nakladatelství Lidové noviny. Praha 2013.
ISBN: 978-80-7422-265-8
Václav Cvrček
Kvantitativní analýza, popsaná v této knize, se zabývá tím, jaké jsou obecné  charakteristiky kontextu, co můžeme považovat za anomální a co za běžné a jak je možné hodnoty v kontextu slov naměřené lingvisticky interpretovat.
charakteristiky kontextu, co můžeme považovat za anomální a co za běžné a jak je možné hodnoty v kontextu slov naměřené lingvisticky interpretovat.
O klíčové povaze kontextu při analýze jazykových jevů se v jazykovědě obecně nepochybuje. Bezesporný je jeho význam při analýze sémantiky slov.
Výsledky zde prezentované tak můžou posloužit jako východisko pro jakákoli jazyková bádání, která se snaží vedle pragmatického aspektu uchopovat i dosud podceňovaný rozměr syntagmatický.
Cvrček, V.: Kvantitativní analýza kontextu. Nakladatelství Lidové noviny. Praha 2013.
ISBN: 978-80-7422-264-1
Věra Schmiedtová
Výběrový výkladový slovník, který se snaží zachytit dobový jazyk, s nímž přicházel v letech  1948-1989 do styku běžný člověk, který nepatřil ani mezi komunisty, ani mezi disidenty.
1948-1989 do styku běžný člověk, který nepatřil ani mezi komunisty, ani mezi disidenty.
Tento jazyk už v současnosti postupně mizí. Heslář byl sestavený na základě speciálního Korpusu totality, který obsahuje tři sondy Rudého práva z různých časových období a 91 naskenovaných propagandistických příruček, a na základě excerpce. Obsahuje více než 1400 hesel. Slovník zachycuje na jedné straně jazyk komunistických vládců – jednotlivá slova oficiální propagandy, slovní kolokace a oblíbené syntaktické struktury. Dále jsou zde slova, která označovala politický a správní systém, ale i represivní zařízení a akce režimu. Na druhé straně je zde i jazyk ovládaných, kterým lidé reagovali na oficiální jazyk. Některá zařazená slova nemají politické pozadí, ale charakterizují dobovou realitu.
Schmiedtová, V.: Malý slovník reálií komunistické totality. Nakladatelství Lidové noviny. Praha 2013.
ISBN: 978-80-7422-192-7
František Čermák
Systematický a úplný popis frekvenčního jádra češtiny po stránce všech jeho prostředků a způsobů, a to v rámci dosud opomíjené širší disciplíny, tvorby pojmenování. Popisují se tu především formální aspekty autosémantických slovních druhů (substantiv, adjektiv, verb i adverbií), významná pozornost se však věnuje i ostatním slovním druhům a poukazuje se na vzájemnou provázanost v rámci vlastní slovotvorby jednak bází a rezultátů, a jednak slovotvorby a kolokací (víceslovných pojmenování). Kniha přináší akcent, tradičně jinde neuplatňovaný, na systémovost popisu zvláště po stránce paradigmatické vedoucí k přehodnocování řady slovotvorných prostředků. Ten je vyvažován pozorností věnovanou aspektům syntagmatickým, např. souvislostem s valencí slova. Do knihy je zařazen vedle hlavní slovotvorné části i málo známý a systematický přehled české morfématiky, kde se najdou poprvé i partie o obtížné české alomorfii.
způsobů, a to v rámci dosud opomíjené širší disciplíny, tvorby pojmenování. Popisují se tu především formální aspekty autosémantických slovních druhů (substantiv, adjektiv, verb i adverbií), významná pozornost se však věnuje i ostatním slovním druhům a poukazuje se na vzájemnou provázanost v rámci vlastní slovotvorby jednak bází a rezultátů, a jednak slovotvorby a kolokací (víceslovných pojmenování). Kniha přináší akcent, tradičně jinde neuplatňovaný, na systémovost popisu zvláště po stránce paradigmatické vedoucí k přehodnocování řady slovotvorných prostředků. Ten je vyvažován pozorností věnovanou aspektům syntagmatickým, např. souvislostem s valencí slova. Do knihy je zařazen vedle hlavní slovotvorné části i málo známý a systematický přehled české morfématiky, kde se najdou poprvé i partie o obtížné české alomorfii.
Čermák, F.: Morfématika a slovotvorba češtiny. Nakladatelství Lidové noviny. Praha 2012.
ISBN 978-80-7422-146-0
Jana Marie Tušková
Práce J. M. Tuškové, kterou přináší tento svazek Studií z korpusové lingvistiky, je  vítaným vhledem do málo a nepřesně poznané oblasti vlastních jmen ženského rodu a jejich skloňování v ČNK, a tedy na taková jména jako Kouřim, Čáslav, Třeboň, Náměšť, Hluboká, Nusle, Stodůlky, Kateřinky, Rokycany či Pardubice. Kvůli množství dat se tu popisují jen necelé dvě tisícovky těch nejfrekventovanějších. Proti dosavadním pracím a slovníkům, založeným na manuálním a ne nutně vždy systematickém sběru, autorka zvolenou oblast popisuje nejen vyčerpávajícím způsobem, ale dává i představu o jejím jádru i případech periferních.
vítaným vhledem do málo a nepřesně poznané oblasti vlastních jmen ženského rodu a jejich skloňování v ČNK, a tedy na taková jména jako Kouřim, Čáslav, Třeboň, Náměšť, Hluboká, Nusle, Stodůlky, Kateřinky, Rokycany či Pardubice. Kvůli množství dat se tu popisují jen necelé dvě tisícovky těch nejfrekventovanějších. Proti dosavadním pracím a slovníkům, založeným na manuálním a ne nutně vždy systematickém sběru, autorka zvolenou oblast popisuje nejen vyčerpávajícím způsobem, ale dává i představu o jejím jádru i případech periferních.
Tušková, J. M.: Deklinační systém femininních oikonym v češtině. Nakladatelství Lidové noviny. Praha 2011.
ISBN 978-80-7422-138-5
František Čermák, ed.
Příspěvky přednesené na konferenci Korpusová lingvistika Praha 2011 pořádané  Ústavem Českého národního korpusu Filozofické fakulty Univerzity Karlovy. Tento svazek se prostřednictvím korpusu InterCorp věnuje srovnávání jazyků na základě paralelních korpusů, a navazuje tak na svazek z konference InterCorp z roku 2010. Z více než 20 v korpusu zastoupených jazyků se zde ve velmi širokém záběru představují příspěvky týkající se 15 z nich. Kontrastivní pohled zvláště z oblastí slovotvorby, lexikonu i gramatiky, založený na autentických datech InterCorpu, tak nabízí významný stimul k dalšímu srovnávacímu výzkumu mnoha jazyků. Ten byl donedávna opomíjen, přestože studium druhého jazyka se stále nejčastěji děje na základě srovnání s jiným jazykem, převážně mateřským, jehož vlastní obraz se zároveň prizmatem druhých jazyků může objektivizovat a zpřesňovat.
Ústavem Českého národního korpusu Filozofické fakulty Univerzity Karlovy. Tento svazek se prostřednictvím korpusu InterCorp věnuje srovnávání jazyků na základě paralelních korpusů, a navazuje tak na svazek z konference InterCorp z roku 2010. Z více než 20 v korpusu zastoupených jazyků se zde ve velmi širokém záběru představují příspěvky týkající se 15 z nich. Kontrastivní pohled zvláště z oblastí slovotvorby, lexikonu i gramatiky, založený na autentických datech InterCorpu, tak nabízí významný stimul k dalšímu srovnávacímu výzkumu mnoha jazyků. Ten byl donedávna opomíjen, přestože studium druhého jazyka se stále nejčastěji děje na základě srovnání s jiným jazykem, převážně mateřským, jehož vlastní obraz se zároveň prizmatem druhých jazyků může objektivizovat a zpřesňovat.
Čermák, F. (ed.): Korpusová lingvistika Praha 2011 – 1 InterCorp. Nakladatelství Lidové noviny. Praha 2011.
ISBN 978-80-7422-114-9
František Čermák, ed.
Příspěvky přednesené na konferenci Korpusová lingvistika Praha 2011 pořádané  Ústavem Českého národního korpusu Filozofické fakulty Univerzity Karlovy. Tento svazek se v prvním tematickém celku věnuje aspektům výstavby korpusů různého druhu, českým i zahraničním, jazykově obecným i specifickým (např. z fonetického, akustického či stylistického hlediska). Vedle převažujícího synchronního pohledu se tu však objevuje i příspěvek věnovaný problematice výstavby diachronního korpusu češtiny. Pozornost je věnována i korpusu romštiny, v rámci obecných příspěvků se tu podává také přehled aktuálního stavu a problematiky výstavby multilingválního korpusu InterCorp.
Ústavem Českého národního korpusu Filozofické fakulty Univerzity Karlovy. Tento svazek se v prvním tematickém celku věnuje aspektům výstavby korpusů různého druhu, českým i zahraničním, jazykově obecným i specifickým (např. z fonetického, akustického či stylistického hlediska). Vedle převažujícího synchronního pohledu se tu však objevuje i příspěvek věnovaný problematice výstavby diachronního korpusu češtiny. Pozornost je věnována i korpusu romštiny, v rámci obecných příspěvků se tu podává také přehled aktuálního stavu a problematiky výstavby multilingválního korpusu InterCorp.
Výsledky vlastního výzkumu převážně synchronních dat představuje druhý tematický celek nabízející korpusově podepřený pohled na aspekty fonologické, morfologické a okrajově i syntaktické. Vedle příspěvků orientovaných na lexikální pragmatiku, možné výukové aplikace, regionální specifiku mluvených korpusů a aspekty oikonym je tento pohled doplňován i příspěvkem věnovaným novému nástroji pro korpusově založený synchronní i diachronní výzkum jazykové variability. Do tohoto svazku jsou také zařazeny tři plenární přednášky.
Čermák, F. (ed.): Korpusová lingvistika Praha 2011 – 2 Výzkum a výstavba korpusů. Nakladatelství Lidové noviny. Praha 2011.
ISBN 978-80-7422-115-6
Vladimír Petkevič, Alexandr Rosen, eds
Příspěvky přednesené na konferenci Korpusová lingvistika Praha 2011 pořádané  Ústavem Českého národního korpusu Filozofické fakulty Univerzity Karlovy. Tento svazek se věnuje dvěma tematickým oblastem. První z nich je věnovaná výzkumu gramatiky v převážně synchronních korpusech, obsahově navazuje na příspěvky ve druhém svazku, především na oddíl Aspekty výzkumu korpusů, a přináší kvalifikované vhledy do oblasti slovotvorby, morfologie, ale i do různých oblastí syntaxe. Na ně navazují i aplikovaně orientované příspěvky s orientací na valenci a další. Druhá oblast je orientovaná spíše technicky a věnuje se různým aspektům syntaktického značkování korpusů. Tematicky ji doplňují příspěvky zabývající se identifikací frazémů a termínů a specifickým žákovským korpusem.
Ústavem Českého národního korpusu Filozofické fakulty Univerzity Karlovy. Tento svazek se věnuje dvěma tematickým oblastem. První z nich je věnovaná výzkumu gramatiky v převážně synchronních korpusech, obsahově navazuje na příspěvky ve druhém svazku, především na oddíl Aspekty výzkumu korpusů, a přináší kvalifikované vhledy do oblasti slovotvorby, morfologie, ale i do různých oblastí syntaxe. Na ně navazují i aplikovaně orientované příspěvky s orientací na valenci a další. Druhá oblast je orientovaná spíše technicky a věnuje se různým aspektům syntaktického značkování korpusů. Tematicky ji doplňují příspěvky zabývající se identifikací frazémů a termínů a specifickým žákovským korpusem.
Petkevič, V., Rosen, A. (eds): Korpusová lingvistika Praha 2011 – 3 Gramatika a značkování korpusů. Nakladatelství Lidové noviny. Praha 2011.
ISBN 978-80-7422-116-3
Václav Cvrček, Ludmila Cvrčková Porkertová
Příručka rýmů usnadní psaní jakýchkoli rýmovaných textů, což je úkol, před kterým  stojí nejen začínající básníci, ale také autoři písňových textů, reklamních sloganů a mnozí další. Slovník zároveň může sloužit jako doplňková pomůcka při výuce literární teorie na základních a středních školách. Svým rozsahem i způsobem zpracování se jedná o unikátní projekt, který na současném knižním trhu nemá obdoby (posledním takovým pokusem byl Puchmajerův Rýmovník z roku 1824).
stojí nejen začínající básníci, ale také autoři písňových textů, reklamních sloganů a mnozí další. Slovník zároveň může sloužit jako doplňková pomůcka při výuce literární teorie na základních a středních školách. Svým rozsahem i způsobem zpracování se jedná o unikátní projekt, který na současném knižním trhu nemá obdoby (posledním takovým pokusem byl Puchmajerův Rýmovník z roku 1824).
Cvrček, V., Cvrčková Porkertová, L.: Velký slovník rýmů. Nakladatelství Lidové noviny, Praha 2011.
ISBN 978-80-7422-095-1
František Čermák, Michal Křen (eds)
Following the lines established by the Routledge Frequency Dictionaries series, the  dictionary is aimed at learners and all other students of Czech. It is the first Czech frequency dictionary based on a balanced selection of both written and authentic spoken Czech (corpora SYN2005, ORAL2006, ORAL2008). It provides the 5,000 most frequently used words in the language listed in a detailed frequency-based index, as well as in alphabetical and part-of-speech indexes. All entries in the rank frequency list feature the English equivalent, a sample sentence with English translation and an indication of register variation.
dictionary is aimed at learners and all other students of Czech. It is the first Czech frequency dictionary based on a balanced selection of both written and authentic spoken Czech (corpora SYN2005, ORAL2006, ORAL2008). It provides the 5,000 most frequently used words in the language listed in a detailed frequency-based index, as well as in alphabetical and part-of-speech indexes. All entries in the rank frequency list feature the English equivalent, a sample sentence with English translation and an indication of register variation.
Čermák, F., Křen, M. (eds): A Frequency Dictionary of Czech: Core Vocabulary for Learners. Routledge, London 2011.
ISBN 978-0-415-57661-1 (hardback)
ISBN 978-0-415-57662-8 (paperback)
ISBN 978-0-415-57663-5 (data CD)
František Čermák, Václav Cvrček, Věra Schmiedtová (eds)
Slovník komunistické totality je prvním pokusem o zmapování jazyka oficiální komunistické propagandy. Slovník vychází z korpusu Totalita, který je založen na třech sondách (roky 1952, 1969 a 1977) do dobového tisku a publikací významně zasažených ideologií. Z různých pohledů se tu zkoumá především lexikon a frazeologie oficiální propagandy, úvodní studie nabízí přehled specifických rysů z oblasti pragmatiky a sémantiky. Slovník je doplněn ukázkami dobových textů a frekvenčním seznamem nejčastějších slov. K publikaci je připojeno CD s úplným korpusem Totalita, který je možné pomocí speciálního obslužného programu prohledávat, a pokračovat tak v započatém výzkumu totalitního jazyka ve specifických, dosud nezkoumaných oblastech.
Čermák, F., Cvrček, V., Schmiedtová, V. (eds): Slovník komunistické totality. Nakladatelství Lidové noviny, Praha 2010.
ISBN 978-80-7422-060-9
František Čermák, Patrick Corness, Aleš Klégr (eds)
Exploration of grammar, lexis, translations, applications, and methodological issues are  studied and illustrated on language pairs or on a group of more languages. This is supplemented by broad and general contributions delineating the field of comparative multilingual corpus linguistics showing possible directions of comparative research based on a multilingual parallel corpus.
studied and illustrated on language pairs or on a group of more languages. This is supplemented by broad and general contributions delineating the field of comparative multilingual corpus linguistics showing possible directions of comparative research based on a multilingual parallel corpus.
Čermák, F., Klégr, A., Corness, P. (eds): InterCorp: Exploring a Multilingual Corpus. Nakladatelství Lidové noviny. Praha 2010.
ISBN 978-80-7422-042-5
František Čermák, Jan Kocek (eds)
Tento svazek je prvním výstupem z mnohojazyčného paralelního korpusu přinášejícím  studie a srovnávací analýzy celkem 13 jazyků (vůči češtině) v oblasti lexikonu, gramatiky, slovotvorby, frazeologie, syntaxe a dalších.
studie a srovnávací analýzy celkem 13 jazyků (vůči češtině) v oblasti lexikonu, gramatiky, slovotvorby, frazeologie, syntaxe a dalších.
Čermák, F., Kocek, J. (eds): Mnohojazyčný korpus InterCorp: Možnosti studia. Nakladatelství Lidové noviny. Praha 2010.
ISBN 978-80-7422-058-6
Mira Načeva-Marvanová
Perfektum v současné češtině nabízí svým čtenářům možnost  podívat se spolu s autorkou do 500-milionové synchronní textové databáze Českého národního korpusu a na základě více než 20 000 dokladů, získaných z této databáze, poznat jedinečnost a překvapující rozmanitost složených forem českého perfekta, které přitom dokládají integraci češtiny do Evropského lingvistického areálu (ELA), respektive i do evropského areálu slovesa mít (tzv. „H-areálu“). Souběžný strukturní popis perfektních forem a konstrukcí je zároveň podroben testováním a analýze, zjišťujícím stav a proces jejich gramatikalizace, která je založena především na auxiliaci slovesa mít, které vystupuje jako iniciátor gramatikalizačního procesu bázových konstrukcí [mít + n-/t-participium], srov. např. máme napsáno, mám natrenováno, máme zaseto, mám to připraveno aj. Práce je opatřena množstvím příkladů, tabulek a frekvenční analýzou jednotlivých typů této konstrukce a jejích struktur.
podívat se spolu s autorkou do 500-milionové synchronní textové databáze Českého národního korpusu a na základě více než 20 000 dokladů, získaných z této databáze, poznat jedinečnost a překvapující rozmanitost složených forem českého perfekta, které přitom dokládají integraci češtiny do Evropského lingvistického areálu (ELA), respektive i do evropského areálu slovesa mít (tzv. „H-areálu“). Souběžný strukturní popis perfektních forem a konstrukcí je zároveň podroben testováním a analýze, zjišťujícím stav a proces jejich gramatikalizace, která je založena především na auxiliaci slovesa mít, které vystupuje jako iniciátor gramatikalizačního procesu bázových konstrukcí [mít + n-/t-participium], srov. např. máme napsáno, mám natrenováno, máme zaseto, mám to připraveno aj. Práce je opatřena množstvím příkladů, tabulek a frekvenční analýzou jednotlivých typů této konstrukce a jejích struktur.
Načeva-Marvanová M.: Perfektum v současné češtině. Nakladatelství Lidové noviny. Praha 2010.
ISBN 978-80-7422-041-8
František Čermák
Kniha podává přehled celého lexikálního systému doplněného o řadu zcela nových a dosud  nemapovaných oblastí jako je tradiční úsek jazykového pojmenování, sémiotické aspekty slova či přehled jeho grafické stránky, začleněny jsou však i přehledy slovotvorby, frazeologie a další. Nově je tu pozornost věnována dosud zcela opomíjeným aspektům syntagmatickým a kombinatorickým.
nemapovaných oblastí jako je tradiční úsek jazykového pojmenování, sémiotické aspekty slova či přehled jeho grafické stránky, začleněny jsou však i přehledy slovotvorby, frazeologie a další. Nově je tu pozornost věnována dosud zcela opomíjeným aspektům syntagmatickým a kombinatorickým.
S omluvou uveřejňujeme seznam chyb nalezených po vydání publikace.
Čermák, F.: Lexikon a sémantika. Nakladatelství Lidové noviny. Praha 2010.
ISBN 978-80-7422-020-3
Věra Schmiedtová
Autorka na základě pilného sledování současného jazyka prostřednictvím korpusů – databází  mluveného, psaného i literárního jazyka zachycených a umožněných počítačovými médii, jejichž objev je prý srovnatelný s vynálezem mikroskopu pro přírodní vědy – začala podávat na přelomu století „zprávy“ o stavu současného jazyka a novinkách v něm posluchačům stanice ČRo 7 – Radio Praha.
mluveného, psaného i literárního jazyka zachycených a umožněných počítačovými médii, jejichž objev je prý srovnatelný s vynálezem mikroskopu pro přírodní vědy – začala podávat na přelomu století „zprávy“ o stavu současného jazyka a novinkách v něm posluchačům stanice ČRo 7 – Radio Praha.
Schmiedtová, V.: Čeština, jak ji neznáte. Nakladatelství Lidové noviny. Praha 2010.
ISBN 978-80-7106-990-4
Josef Šimandl
Desátý svazek řady Studie z korpusové lingvistiky mapuje skloňování skupiny substantiv,  která po historicky dlouhou dobu kolísají ve 3 pádech singuláru mezi měkkým a tvrdým skloňováním. Práce přináší i sondy do elektronicky přístupného diachronního materiálu. Při popisu jsou konfrontována data podle různých korpusů i podle jiných zdrojů, především podle internetu.
která po historicky dlouhou dobu kolísají ve 3 pádech singuláru mezi měkkým a tvrdým skloňováním. Práce přináší i sondy do elektronicky přístupného diachronního materiálu. Při popisu jsou konfrontována data podle různých korpusů i podle jiných zdrojů, především podle internetu.
Šimandl, J.: Dnešní skloňování substantiv typů kámen, břímě. Nakladatelství Lidové noviny. Praha 2010.
ISBN 978-80-7422-008-1
Václav Cvrček, Vilém Kodýtek, Marie Kopřivová, Dominika Kováříková, Petr Sgall, Michal Šulc, Jan Táborský, Jan Volín, Martina Waclawičová
Mluvnice současné češtiny autorů působících na Filozofické fakultě a Matematicko- fyzikální fakultě Univerzity Karlovy je po téměř patnácti letech novým pokusem o stručný a srozumitelný popis našeho mateřského jazyka. Mluvnice je koncipována jako dvoudílná, přičemž první díl zahrnuje poučení mj. o zvukové stránce jazyka, slovní zásobě, slovotvorbě, tvarosloví, stylistice a psací soustavě (druhý díl pak bude věnován větné skladbě). Jako vůbec první popis svého druhu se mluvnice pokouší systematicky zachycovat rozdíl mezi mluvenou a psanou češtinou a to na základě rozsáhlých dat z Českého národního korpusu. Výsledkem je materiálově založená moderní a přehledná publikace, která nepodává obraz o tom, jak by jazyk vypadat měl, ale o tom, jak skutečně mluvíme a píšeme. Čtenář si tak může sám udělat obrázek o tom, jaké způsoby vyjadřování jsou obvyklé a vhodné pro určitou situaci a které prostředky jsou naopak nevšední či v daném kontextu nepreferované.
fyzikální fakultě Univerzity Karlovy je po téměř patnácti letech novým pokusem o stručný a srozumitelný popis našeho mateřského jazyka. Mluvnice je koncipována jako dvoudílná, přičemž první díl zahrnuje poučení mj. o zvukové stránce jazyka, slovní zásobě, slovotvorbě, tvarosloví, stylistice a psací soustavě (druhý díl pak bude věnován větné skladbě). Jako vůbec první popis svého druhu se mluvnice pokouší systematicky zachycovat rozdíl mezi mluvenou a psanou češtinou a to na základě rozsáhlých dat z Českého národního korpusu. Výsledkem je materiálově založená moderní a přehledná publikace, která nepodává obraz o tom, jak by jazyk vypadat měl, ale o tom, jak skutečně mluvíme a píšeme. Čtenář si tak může sám udělat obrázek o tom, jaké způsoby vyjadřování jsou obvyklé a vhodné pro určitou situaci a které prostředky jsou naopak nevšední či v daném kontextu nepreferované.
Cvrček, V. a kol.: Mluvnice současné češtiny. Nakladatelství Karolinum, Praha 2010.
ISBN 978-80-246-1743-5
Tomáš Bartoň, Václav Cvrček, František Čermák, Tomáš Jelínek, Vladimír Petkevič
Příručka umožňuje uživateli udělat si ucelenou představu o frekventovaném jádru  fonologických, morfologických a syntagmatických jevů v češtině na jedné straně a perifériích jazykového systému na straně druhé, což je informace, kterou klasické gramatické příručky podávají zřídka, nebo ji – ve většině případů – úplně opomíjejí. Doplňuje se tak popis systému češtiny o důležitý aspekt frekvenční, který nám jednoznačně ukazuje, že často je věnována intenzivní pozornost jevům marginálním, zatímco rozsáhlé neprobádané oblasti jevů frekventovaných (např. problematika kombinatoriky slovních druhů) zůstávají nepovšimnuty.
fonologických, morfologických a syntagmatických jevů v češtině na jedné straně a perifériích jazykového systému na straně druhé, což je informace, kterou klasické gramatické příručky podávají zřídka, nebo ji – ve většině případů – úplně opomíjejí. Doplňuje se tak popis systému češtiny o důležitý aspekt frekvenční, který nám jednoznačně ukazuje, že často je věnována intenzivní pozornost jevům marginálním, zatímco rozsáhlé neprobádané oblasti jevů frekventovaných (např. problematika kombinatoriky slovních druhů) zůstávají nepovšimnuty.
S omluvou uveřejňujeme seznam chyb nalezených po vydání publikace.
Bartoň, T. a kol.: Statistiky češtiny. Nakladatelství Lidové noviny, Praha 2009.
ISBN 978-80-7106-5944
František Čermák, Václav Cvrček (eds)
Slovník Bohumila Hrabala je pokusem o komplexní popis jazyka výjimečného slovesného  tvůrce druhé poloviny 20. století. Z různých pohledů se tu zkoumá Hrabalův lexikon, specifičnosti jeho morfologie i frazeologie, stejně jako statistické aspekty jeho tvorby. Vedle úplného slovníku Hrabalových lexémů zde čtenář najde i soubor Hrabalových myšlenek a originálních výroků. K publikaci je připojeno CD, které obsahuje kompletní korpus Hrabalových děl spolu s obslužným programem, seznamy hrabalovských kolokací a frekvenční slovník.
tvůrce druhé poloviny 20. století. Z různých pohledů se tu zkoumá Hrabalův lexikon, specifičnosti jeho morfologie i frazeologie, stejně jako statistické aspekty jeho tvorby. Vedle úplného slovníku Hrabalových lexémů zde čtenář najde i soubor Hrabalových myšlenek a originálních výroků. K publikaci je připojeno CD, které obsahuje kompletní korpus Hrabalových děl spolu s obslužným programem, seznamy hrabalovských kolokací a frekvenční slovník.
Čermák, F. – Cvrček, V..: Slovník Bohumila Hrabala. Nakladatelství Lidové noviny, Praha 2009.
ISBN 978-80-7106-488-6
Anna Čermáková
Valence substantiv se v knize pojímá jako jev lexikologický pro substantiva svébytný, a  nikoli (nutně) odvozený od sloves, mající ve svém úhrnu povahu odlišnou a výrazně sémantickou, což naznačuje i řada uváděných subklasifikací. Pojetí valence a zvláště jejích formálních exponentů se přitom soustřeďuje na všechny formální a kategoriální rysy, které ji v korpusu vyjadřují, bez apriorní (a zpravidla omezující) teorie.
nikoli (nutně) odvozený od sloves, mající ve svém úhrnu povahu odlišnou a výrazně sémantickou, což naznačuje i řada uváděných subklasifikací. Pojetí valence a zvláště jejích formálních exponentů se přitom soustřeďuje na všechny formální a kategoriální rysy, které ji v korpusu vyjadřují, bez apriorní (a zpravidla omezující) teorie.
Čermáková, A.: Valence českých substantiv. Nakladatelství Lidové noviny, Praha 2009.
ISBN 978-80-7106-426-800
Václav Cvrček
Tento svazek představuje první pokus, jak na základě korpusových metod vystavět plán  jazykově regulační činnosti založené na minimální intervenci do jazyka a řečové činnosti – Koncept minimální intervence (KMI). Přijatým předpokladem tohoto konceptu je fakt, že jazyk se samovolně vyvíjí v účelný nástroj dorozumívání bez pomoci ze strany lingvistů, a není proto důvod, proč by jazykověda měla do vývoje jazyka svými preskriptivními intervencemi zasahovat. V polemice s předcházejícími koncepty jazykově regulační činnosti (Teorie jazykové kultury, puristický koncept apod.) vychází KMI striktně z informací, které nám o jazykových prostředcích může poskytnout korpus, mezi něž nepatří kritéria hodnocení na ose spisovný – nespisovný (nebo správný – nesprávný). Zároveň tato publikace přináší obecnější Teorii intervencí, která slouží jako zastřešující teoretický model nad jednotlivými koncepty jazykově regulační činnosti, a korpusové sondy měřící míru preskriptivismu v českém prostředí a dopad kodifikačních intervencí na jazyk.
jazykově regulační činnosti založené na minimální intervenci do jazyka a řečové činnosti – Koncept minimální intervence (KMI). Přijatým předpokladem tohoto konceptu je fakt, že jazyk se samovolně vyvíjí v účelný nástroj dorozumívání bez pomoci ze strany lingvistů, a není proto důvod, proč by jazykověda měla do vývoje jazyka svými preskriptivními intervencemi zasahovat. V polemice s předcházejícími koncepty jazykově regulační činnosti (Teorie jazykové kultury, puristický koncept apod.) vychází KMI striktně z informací, které nám o jazykových prostředcích může poskytnout korpus, mezi něž nepatří kritéria hodnocení na ose spisovný – nespisovný (nebo správný – nesprávný). Zároveň tato publikace přináší obecnější Teorii intervencí, která slouží jako zastřešující teoretický model nad jednotlivými koncepty jazykově regulační činnosti, a korpusové sondy měřící míru preskriptivismu v českém prostředí a dopad kodifikačních intervencí na jazyk.
Cvrček, V.: Regulace jazyka a Koncept minimální intervence. Nakladatelství Lidové noviny, Praha 2008.
ISBN 978-80-7106-600-2
Marie Kopřivová, Martina Waclawičová (eds)
Svazek přináší soubor příspěvků z mezinárodní a interdisciplinární konference Čeština v  mluveném korpusu konané v roce 2007 na Filozofické fakultě Univerzity Karlovy v Praze. Texty se shodně věnují velmi aktuální a dříve opomíjené mluvené formě jazyka z hlediska řady aspektů. Představují ji tak, jak je zachycena v různých autentických mluvených korpusech, a podrobují ji zkoumání korpusovými metodami. Témata knihy, první svého druhu, zahrnují široké pole od problematiky budování mluvených korpusů přes zkoumání obecných rysů mluvenosti a variantnosti v mluveném jazyce až po různé aspekty gramatického popisu mluveného jazyka.
mluveném korpusu konané v roce 2007 na Filozofické fakultě Univerzity Karlovy v Praze. Texty se shodně věnují velmi aktuální a dříve opomíjené mluvené formě jazyka z hlediska řady aspektů. Představují ji tak, jak je zachycena v různých autentických mluvených korpusech, a podrobují ji zkoumání korpusovými metodami. Témata knihy, první svého druhu, zahrnují široké pole od problematiky budování mluvených korpusů přes zkoumání obecných rysů mluvenosti a variantnosti v mluveném jazyce až po různé aspekty gramatického popisu mluveného jazyka.
Kopřivová, M. – Waclawičová (eds): Čeština v mluveném korpusu. Nakladatelství Lidové noviny, Praha 2008.
ISBN 978-80-7106-982-9
Jitka Šonková
Tento svazek podává první soustavnou charakteristiku skloňování a časování v mluvené  češtině. Studie vychází z kvantitativní analýzy Pražského mluveného korpusu, tvořeného přepisy více než 304 nahrávek z Prahy a okolí, a zaměřuje se především na konkurenci spisovných a nespisovných tvarů v běžné komunikaci českých mluvčích.
češtině. Studie vychází z kvantitativní analýzy Pražského mluveného korpusu, tvořeného přepisy více než 304 nahrávek z Prahy a okolí, a zaměřuje se především na konkurenci spisovných a nespisovných tvarů v běžné komunikaci českých mluvčích.
Šonková, J.: Morfologie mluvené češtiny: Frekvenční analýza. Nakladatelství Lidové noviny, Praha 2008.
ISBN 978-80-7106-956-0
František Čermák (ed.)
Tímto svazkem se začíná nová řada v sérii korpusových publikací o jazyku nazvaná  Korpusová lexikografie. Představí postupně řadu slovníků určitého důležitého období či autorských slovníků významných jednotlivců národní kultury, které zpravila není třeba představovat a kteří se významně podepsali na podobě své doby i jejího jazyka. Prvním v této řadě je Slovník Karla Čapka, jednoho z nejvýznamnějších českých spisovatelů a myslitelů vůbec.
Korpusová lexikografie. Představí postupně řadu slovníků určitého důležitého období či autorských slovníků významných jednotlivců národní kultury, které zpravila není třeba představovat a kteří se významně podepsali na podobě své doby i jejího jazyka. Prvním v této řadě je Slovník Karla Čapka, jednoho z nejvýznamnějších českých spisovatelů a myslitelů vůbec.
Slovník Karla Čapka mapuje Čapkův jazyk v řadě parametrů a způsobem, jakým dřívější a většinou ručně sestavované slovníky slavných autorů (od antiky přes Shakespeara až po Otokara Březinu) postupovat nemohly. Vedle vlastního slovníku tu zájemce najde nejenom několik odborných studií, ale také soubor Čapkových myšlenek k jeho době. Kniha je doprovázena CD s korpusem celého Čapkova díla v počítačové podobě, díky němuž se uživateli nabízí široká možnost vlastního studia celého materiálu, na kterém je slovník založen.
S omluvou uveřejňujeme seznam chyb nalezených po vydání slovníku.
Čermák, F. (ed.): Slovník Karla Čapka. Nakladatelství Lidové noviny, Praha 2007
ISBN 978-80-7106-915-7
František Čermák (ed.)
Frekvenční slovník mluvené češtiny je vůbec první slovník svého druhu, představující  autentickou mluvenou češtinu, která tu stojí v protikladu k češtině spisovné a psané. Ukazuje, jak lidé skutečně mluví, tj. bez kodifikačních zásahů a deformací. Slovník vychází z Pražského mluveného korpusu, založeného na sociolingvisticky reprezentativních nahrávkách rozhovorů. Na přiloženém CD je k dispozici celý tento korpus i s obslužným programem, pomocí kterého si uživatel může podle zájmu vyhledávat mnoho dalšího, a to především v autentickém kontextu, kde se daný skutečně výraz užívá. Nabízí se tu takto mimořádná možnost studia skutečného mluveného jazyka v kontextu včetně jeho statistického vyhodnocení, která až dosud k dispozici nebyla ani pro vědecké ani například pedagogické účely.
autentickou mluvenou češtinu, která tu stojí v protikladu k češtině spisovné a psané. Ukazuje, jak lidé skutečně mluví, tj. bez kodifikačních zásahů a deformací. Slovník vychází z Pražského mluveného korpusu, založeného na sociolingvisticky reprezentativních nahrávkách rozhovorů. Na přiloženém CD je k dispozici celý tento korpus i s obslužným programem, pomocí kterého si uživatel může podle zájmu vyhledávat mnoho dalšího, a to především v autentickém kontextu, kde se daný skutečně výraz užívá. Nabízí se tu takto mimořádná možnost studia skutečného mluveného jazyka v kontextu včetně jeho statistického vyhodnocení, která až dosud k dispozici nebyla ani pro vědecké ani například pedagogické účely.
Čermák, F. (ed.): Frekvenční slovník mluvené češtiny. Karolinum, Praha 2007.
ISBN 978-80-246-1425-0
François Esvan
Tento svazek představuje podrobný popis vidové morfologie českých sloves z hlediska  jejich tvoření, a to na základě stomiliónového korpusu současné češtiny SYN2000. Tento popis je zachycen v podobě relační databáze obsahující údaje o frekvenci všech sloves nacházejících se v korpusu SYN2000 a o vztazích mezi těmito lexémy z vidového hlediska. Detailně jsou zpracovány a frekvenčně zachyceny způsoby tvoření vidových derivátů: prefixace, sufixace a iterativní sufixace.
jejich tvoření, a to na základě stomiliónového korpusu současné češtiny SYN2000. Tento popis je zachycen v podobě relační databáze obsahující údaje o frekvenci všech sloves nacházejících se v korpusu SYN2000 a o vztazích mezi těmito lexémy z vidového hlediska. Detailně jsou zpracovány a frekvenčně zachyceny způsoby tvoření vidových derivátů: prefixace, sufixace a iterativní sufixace.
Esvan, F.: Vidová morfologie českého slovesa. Nakladatelství Lidové noviny, Praha 2007.
ISBN 978-80-7106-913-300
Marie Kopřivová
Tato práce se věnuje valenci českých adjektiv a využívá při tom rozsáhlého korpusového  materiálu, který poskytuje korpus psané češtiny SYN2000. Jejím východiskem je lexikologické pojetí valence a zaměřuje se na popis formálních exponentů adjektivní valence. Nejedná se o vyčerpávající popis valence adjektiv, spíše o naznačení možností, jak k jejímu zkoumání využít korpusový materiál.
materiálu, který poskytuje korpus psané češtiny SYN2000. Jejím východiskem je lexikologické pojetí valence a zaměřuje se na popis formálních exponentů adjektivní valence. Nejedná se o vyčerpávající popis valence adjektiv, spíše o naznačení možností, jak k jejímu zkoumání využít korpusový materiál.
Kopřivová, M.: Valence českých adjektiv. Nakladatelství Lidové noviny, Praha 2006.
ISBN 80-7106-862-4
Renata Blatná
Tento svazek představuje všeobecný popis víceslovných předložek, např. (v rámci  něčeho, vzhledem k něčemu, spolu s něčím), kterých jsou v jazyce řádově stovky (kolem 400). Od jednoslovných předložek, např. (v, na, proti) apod., kterých jsou řádově desítky, se víceslovné předložky liší především sémanticky. Uvedený popis víceslovných předložek vychází z velkého korpusu SYN2000 a navazuje na zpracování těchto jednotek ve Slovníku české frazeologie a idiomatiky. Výrazy neslovesné.
něčeho, vzhledem k něčemu, spolu s něčím), kterých jsou v jazyce řádově stovky (kolem 400). Od jednoslovných předložek, např. (v, na, proti) apod., kterých jsou řádově desítky, se víceslovné předložky liší především sémanticky. Uvedený popis víceslovných předložek vychází z velkého korpusu SYN2000 a navazuje na zpracování těchto jednotek ve Slovníku české frazeologie a idiomatiky. Výrazy neslovesné.
Blatná, R.: Víceslovné předložky v současné češtině. Nakladatelství Lidové noviny, Praha 2006.
ISBN 80-7106-865-9
František Čermák, Michal Šulc (eds)
Svazek Kolokace je tematickým sborníkem, prvním českým věnovaným dané oblasti.  Téma kolokací, „společného výskytu slov“, je dnes centrálním pojmem korpusové lingvistiky, jehož rozmanitost a rozpětí od víceslovných termínů a idiomů až k náhodným kombinacím klade na uchopení problematiky i její zpracování velké nároky.
Téma kolokací, „společného výskytu slov“, je dnes centrálním pojmem korpusové lingvistiky, jehož rozmanitost a rozpětí od víceslovných termínů a idiomů až k náhodným kombinacím klade na uchopení problematiky i její zpracování velké nároky.
Čermák, F. – Šulc, M. (eds): Kolokace. Nakladatelství Lidové noviny, Praha 2006.
ISBN 80-7106-863-2
František Čermák, Renata Blatná (eds)
Tento svazek předkládá čtenářům korpusově založené studie  (tzv. case studies), které se věnují takovým základním jazykovým jevům a problémům, jako je např. hranice mezi lexikonem a gramatikou, hranice mezi psaným a mluveným jazykem apod., jejichž řešení lze chápat jako modelové pro zkoumání obdobných případů, tj. jejichž závěry lze extrapolovat.
(tzv. case studies), které se věnují takovým základním jazykovým jevům a problémům, jako je např. hranice mezi lexikonem a gramatikou, hranice mezi psaným a mluveným jazykem apod., jejichž řešení lze chápat jako modelové pro zkoumání obdobných případů, tj. jejichž závěry lze extrapolovat.
Čermák, F. – Blatná, R. (eds): Korpusová lingvistika: Stav a modelové přístupy. Nakladatelství Lidové noviny, Praha 2006.
ISBN 80-7106-861-6
František Čermák, Renata Blatná (eds)
Studijní pomůcka pro přemýšlivé studenty středních škol, žáky vyšších ročníků  základních škol i studenty vysokoškolské, kteří chtějí vniknout do zákonitostí českého jazyka poněkud jinak, než je v tradičníchučebnicích obvyklé. Pracuje se s Českým národním korpusem, který při svém rozsahu 100 mil. slovních tvarů umožňuje interpretovat jazykové jevy ze zcela nových hledisek, především s využitím frekvence slov a tvarů a různých statistických funkcí. Příručka provede studenta jednoduchým i detailně sofistikovaným vyhledáváním jazykových jevů v Českém národním korpusu i problematikou spojenou s různými jazykovými rovinami od hláskosloví až po slovní zásobu a slovní spojení (kolokace). Na své si při práci s touto knihou přijdou především ti pedagogové a studenti, které baví práce s počítačem a současně je zajímá naše mateřština. Přemýšlivějším a otevřenějším se tu nabízí inspirativní cesta, jak překonat dříve neslučitelné zájmy, češtinu a matematiku.
základních škol i studenty vysokoškolské, kteří chtějí vniknout do zákonitostí českého jazyka poněkud jinak, než je v tradičníchučebnicích obvyklé. Pracuje se s Českým národním korpusem, který při svém rozsahu 100 mil. slovních tvarů umožňuje interpretovat jazykové jevy ze zcela nových hledisek, především s využitím frekvence slov a tvarů a různých statistických funkcí. Příručka provede studenta jednoduchým i detailně sofistikovaným vyhledáváním jazykových jevů v Českém národním korpusu i problematikou spojenou s různými jazykovými rovinami od hláskosloví až po slovní zásobu a slovní spojení (kolokace). Na své si při práci s touto knihou přijdou především ti pedagogové a studenti, které baví práce s počítačem a současně je zajímá naše mateřština. Přemýšlivějším a otevřenějším se tu nabízí inspirativní cesta, jak překonat dříve neslučitelné zájmy, češtinu a matematiku.
Hlavní části:
Práce s ČNK krok za krokem – úkoly na jevy z hláskosloví, tvoření slov, tvarosloví, slovní zásoby, syntaxe a slovních spojení.
Co říká o různých slovech korpus a co slovníky – úkoly na zjištění významu méně frekventovaných slov.
Význam slova prozrazuje kontext – úkoly, v nichž je třeba na základě kontextu odhalit vynechané slovo nebo slovní spojení, popř. odlišit slova formálně podobná.
Úkoly pro náročnější – úkoly na zadávání sofistikovaných korpusových dotazů.
Práce se subkorpusy – úkoly s různými typy textu.
Studijní příručka Jak využívat ČNK byla na jaře 2007 vydána v reedici s opravami, které nabízíme ke stažení ve formátech RTF a PDF.
Čermák, F. – Blatná, R. (eds): Jak využívat Český národní korpus. Nakladatelství Lidové noviny, Praha 2005.
ISBN 80-7106-736-9
Renata Blatná, Vladimír Petkevič (eds)
Při příležitosti 65. narozenin prof. Františka Čermáka vyšel sborník Jazyky a  jazykověda. Sborník představuje práce kolegů a doktorandů prof. Františka Čermáka z různých oblastí jeho odborného zájmu, neboť jubilující prof. František Čermák svými publikacemi zasáhl do mnoha lingvistických oborů a navíc se stal průkopníkem naprosto nového oboru, korpusové lingvistiky. Svými kolegy a studenty však není vnímán pouze jako vědec světového věhlasu, ale také jako skvělý člověk a organizátor, který dokázal podnítit řadu spolupracovníků k práci na projektech světového významu, a neméně skvělý pedagog, který mezi studenty zasel řadu obecnělingvistických, frazeologických a korpusových „semínek“.
jazykověda. Sborník představuje práce kolegů a doktorandů prof. Františka Čermáka z různých oblastí jeho odborného zájmu, neboť jubilující prof. František Čermák svými publikacemi zasáhl do mnoha lingvistických oborů a navíc se stal průkopníkem naprosto nového oboru, korpusové lingvistiky. Svými kolegy a studenty však není vnímán pouze jako vědec světového věhlasu, ale také jako skvělý člověk a organizátor, který dokázal podnítit řadu spolupracovníků k práci na projektech světového významu, a neméně skvělý pedagog, který mezi studenty zasel řadu obecnělingvistických, frazeologických a korpusových „semínek“.
Blatná, R. – Petkevič, V. (eds): Jazyky a jazykověda. Sborník k 65. narozeninám prof. Františka Čermáka. ÚČNK FF UK, Praha 2005.
ISBN 80-7308-079-6
František Čermák, Michal Křen (eds)
Koncem listopadu 2004 byl vydán v Nakladatelství Lidové noviny Frekvenční slovník  češtiny. Je založen na korpusu FSC2000, jehož složení bylo proporčně vyváženo tak, aby věrně zachycovalo současný psaný jazyk. Korpus byl zpracován automatickými metodami, po kterých však následovaly rozsáhlé manuální korekce. Tento lingvistický vklad spolu s dostatečně velkým reprezentativním korpusem, na němž je slovník založen, zajišťují vysokou spolehlivost předkládaných dat.
češtiny. Je založen na korpusu FSC2000, jehož složení bylo proporčně vyváženo tak, aby věrně zachycovalo současný psaný jazyk. Korpus byl zpracován automatickými metodami, po kterých však následovaly rozsáhlé manuální korekce. Tento lingvistický vklad spolu s dostatečně velkým reprezentativním korpusem, na němž je slovník založen, zajišťují vysokou spolehlivost předkládaných dat.
V hlavní části slovníku najdete:
Z dodatků se dále dozvíte:
Ke slovníku je přiložené CD, které umožňuje pohodlné prohlížení hesláře v elektronické podobě, jeho třídění a prohledávání podle nejrůznějších kritérií, a samozřejmě také ukládání vybraných hesel pro další zpracování.
Čermák, F. – Křen, M. (eds): Frekvenční slovník češtiny. Nakladatelství Lidové noviny, Praha 2004.
ISBN 80-7106-676-1
{kind=link}